Day 113: Implementing Tiered Storage for Log Data
Day 113: Implementing Tiered Storage for Log Data
Working Code Demo:
Today's Build Agenda
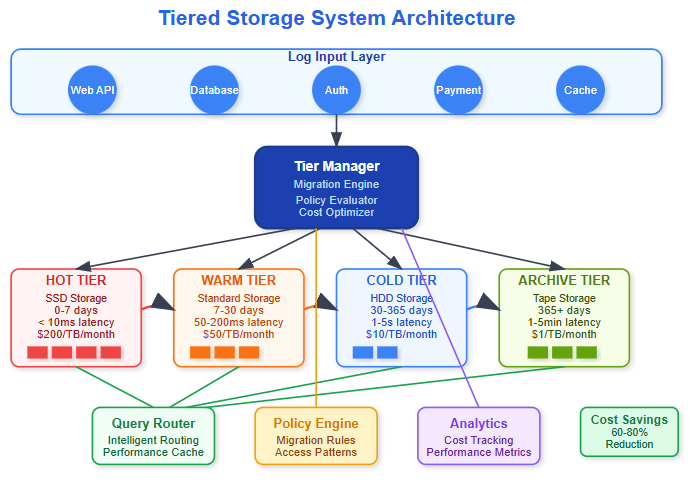
You'll implement an intelligent tiered storage system that automatically moves log data across four storage tiers based on age, access patterns, and cost optimization. This enterprise-grade feature reduces storage costs by 60-80% while maintaining query performance.
What We're Building:
Core Concepts: Intelligent Data Lifecycle Management
Tiered storage transforms static data storage into a dynamic, cost-aware system. Instead of keeping all logs on expensive high-performance storage, data automatically migrates based on access patterns and business rules.
Key Design Principles:
Real-world impact: Netflix saves millions annually by moving viewing logs from expensive NVMe storage to glacier archives after 90 days, while keeping recent data hot for recommendation algorithms.
Context in Distributed Systems
[
](https://substackcdn.com/image/fetch/$s!jQ3f!,fauto,qauto:good,flprogressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F1a140536-2119-4124-ad8e-192ed08c3564_691x493.png)
Tiered storage sits at the intersection of storage management, cost optimization, and performance engineering. In distributed log processing, it enables horizontal scaling without linear cost increases.
System Integration Points:
Your tiered storage integrates with previous components: authentication (Day 112) ensures only authorized users access archived data, while upcoming lifecycle policies (Day 114) will define retention rules across tiers.
[Read more](https://sdcourse.substack.com/p/day-113-implementing-tiered-storage)
You can include dynamic values by using placeholders like: https://drewdru.syndichain.com/articles/4cf5d8ea-3c3a-4d32-bf5d-f9d03dd31078 , Drew Dru, https://sdcourse.substack.com/p/day-113-implementing-tiered-storage , drewdru, drewdru, drewdru, drewdru These will automatically be replaced with the actual data when the message is sent.